











What Scraping Solutions Does AntsData Provide?
Discover AntsData's powerful web scraping solutions. Choose between ready-to-use standardized APIs or fully customized scraping services tailored to your business needs.
This tutorial covers Python web scraping in 10 steps, detailing tools, techniques, ethical guidelines, and practical applications like data extraction, analysis, and competitor monitoring.
Web scraping is a powerful skill that allows you to extract data from websites for various purposes, such as data analysis, price monitoring, or competitor research. In this web scraping Python tutorial, we'll outline everything needed to get started with a simple application. You’ll learn:
· Setting up the environment for web scraping.
· Understanding website structures.
· Writing Python scripts to scrape data.
· Handling challenges like dynamic content and anti-scraping measures.
If you’re new to web scraping or want to refine your skills, this step-by-step guide will walk you through the process, from setting up your environment to extracting data efficiently and ethically.
Web scraping is the process of using scripts or tools to extract data from websites. Instead of manually copying information, web scraping automates this task using Python libraries like Beautiful Soup, Scrapy, and Selenium. Common applications include:
· Tracking e-commerce prices.
· Aggregating reviews and ratings.
· Gathering market research data.
Some of the most prominent applications of web scraping:
· Market research
· Price monitoring
· AI development
· SERP analysis
· Dynamic pricing
· Ad verification
· Travel fare aggregation
· Threat intelligence
This tutorial will focus on using Python for web scraping and guide you through 10 essential steps to scrape data effectively.
Before diving into web scraping, ensure you have the right tools and environment:
1. Python: Install the latest version from python.org.
2. Pip: Comes bundled with Python to manage packages.
3. Libraries:
o Beautiful Soup: For HTML parsing.
o Requests: To fetch webpage content.
o Pandas: To store and manipulate data.
o Optionally, Selenium: For scraping dynamic content.
Installation Commands

Scraping success depends on understanding the structure of your target website.
Inspect the Website
1. Open the website in your browser.
2. Right-click and select Inspect (or press Ctrl + Shift + I).
3. Use the Elements tab to explore the HTML structure.
4. Identify the tags (e.g., <div>, <span>, <table>) and classes that contain the data you need.
Example
For instance, if you’re scraping product prices, look for elements like:
Use the requests library to retrieve HTML content.
Code Example
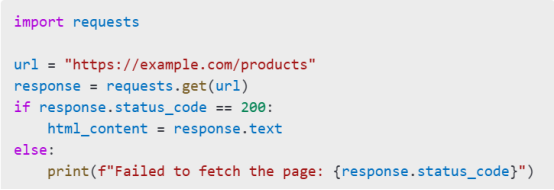
Tips
· Check the status_code to ensure the request was successful.
· Handle errors gracefully to avoid breaking your script.
· Beautiful Soup makes it easy to extract data from HTML.
· Code Example
Key Methods
· find(): Fetches the first matching element.
· find_all(): Fetches all matching elements.
· select(): Fetches elements using CSS selectors.
Some websites use JavaScript to load content dynamically. Selenium can interact with such sites like a real user.
Code Example
Advantages of Selenium
· Handles JavaScript-heavy websites.
· Simulates user interactions (e.g., clicks, scrolling).
Organizing your data is crucial for further analysis. Use Pandas to store data in a structured format.
Code Example
Tips
· Use JSON for hierarchical data.
· Validate data before saving to ensure accuracy.
Web scraping requires ethical and technical diligence:
Best Practices
1. Respect robots.txt: Check the website’s robots.txt file for scraping permissions.
2. Rate Limiting: Avoid sending requests too frequently to prevent IP bans.
3. User-Agent Rotation: Rotate User-Agent headers to mimic different browsers.
Example: User-Agent Rotation
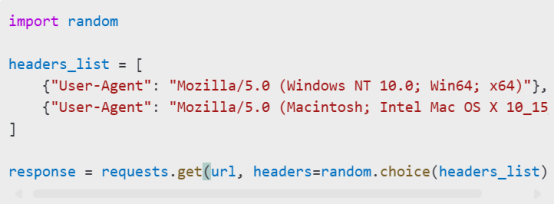
Websites may deploy measures to block scrapers. Use proxies and CAPTCHA-solving techniques:
Using Proxies
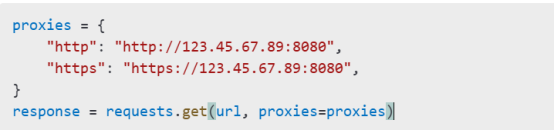
Solving CAPTCHAs
Use services like 2Captcha or Death by CAPTCHA for automated solutions.
Do’s
· Attribute data sources when using scraped data.
· Scrape only publicly available data.
Don’ts
· Avoid scraping sensitive or private information.
· Don’t overload servers with excessive requests.
Testing
· Use smaller datasets to test your scraper.
· Debug errors and refine your code.
Optimization Tips
· Implement multi-threading for faster scraping.
· Monitor and log errors to improve reliability.
Case Study: Scraping E-commerce Prices
To put the above steps into practice, let’s look at a real-world scenario of scraping e-commerce prices.
Scenario
You need to track product prices from an e-commerce website to monitor competitors' pricing trends.
Steps
1. Target Website: Identify a website like example-ecommerce.com.
2. Inspect HTML: Locate price and product name tags, e.g.,

3. Write the Script:

4.Output: The script saves product names and prices to a CSV file for analysis.
Results
This approach enables you to monitor competitor pricing trends efficiently and adapt your strategy accordingly.
Web scraping can be a powerful tool, but it's essential to stay within legal and ethical boundaries to avoid potential lawsuits, bans, or damage to your reputation. Here’s what you need to know:
Before scraping, review the website's ToS. Some websites explicitly prohibit automated data extraction. Scraping such sites without permission could lead to legal consequences.
The robots.txt file on a website specifies which parts are off-limits to crawlers. While it's not legally binding, ignoring it can be considered unethical and might signal to the website that you are a bad actor.
Extracting personal information, such as user profiles or contact details, can violate privacy laws like GDPR in Europe or CCPA in California. Ensure the data you collect is publicly available and non-sensitive.
Flooding a server with requests can disrupt its operations. Implement rate limits and randomize request intervals to minimize impact and avoid detection.
For large-scale or long-term projects, consider reaching out to website owners to seek permission. A mutually beneficial arrangement can ensure compliance and smooth operations.
When using scraped data in reports, articles, or applications, give credit to the original source. This maintains transparency and builds trust.
A retail company needed to monitor competitors' pricing. They contacted the websites they wanted to scrape, received permission, and agreed on a scraping schedule that wouldn't overwhelm the servers.
By adhering to these guidelines, you can ensure your scraping activities remain compliant and ethical, safeguarding both your project and reputation.
Web scraping is a powerful skill that allows you to extract data from websites for various purposes, such as data analysis, price monitoring, or competitor research. In this web scraping Python tutorial, we'll outline everything needed to get started with a simple application. You’ll learn:
· Setting up the environment for web scraping.
· Understanding website structures.
· Writing Python scripts to scrape data.
· Handling challenges like dynamic content and anti-scraping measures.
If you’re new to web scraping or want to refine your skills, this step-by-step guide will walk you through the process, from setting up your environment to extracting data efficiently and ethically.
Web scraping is the process of using scripts or tools to extract data from websites. Instead of manually copying information, web scraping automates this task using Python libraries like Beautiful Soup, Scrapy, and Selenium. Common applications include:
· Tracking e-commerce prices.
· Aggregating reviews and ratings.
· Gathering market research data.
Some of the most prominent applications of web scraping:
· Market research
· Price monitoring
· AI development
· SERP analysis
· Dynamic pricing
· Ad verification
· Travel fare aggregation
· Threat intelligence
This tutorial will focus on using Python for web scraping and guide you through 10 essential steps to scrape data effectively.
Before diving into web scraping, ensure you have the right tools and environment:
Required Tools
4. Python: Install the latest version from python.org.
5. Pip: Comes bundled with Python to manage packages.
6. Libraries:
o Beautiful Soup: For HTML parsing.
o Requests: To fetch webpage content.
o Pandas: To store and manipulate data.
o Optionally, Selenium: For scraping dynamic content.
Installation Commands

Scraping success depends on understanding the structure of your target website.
Inspect the Website
5. Open the website in your browser.
6. Right-click and select Inspect (or press Ctrl + Shift + I).
7. Use the Elements tab to explore the HTML structure.
8. Identify the tags (e.g., <div>, <span>, <table>) and classes that contain the data you need.
Example
For instance, if you’re scraping product prices, look for elements like:
Use the requests library to retrieve HTML content.
Code Example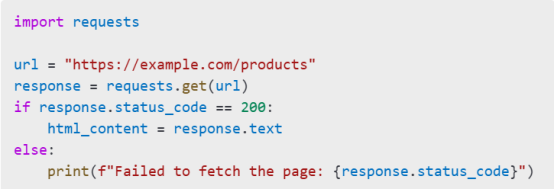
Tips
· Check the status_code to ensure the request was successful.
· Handle errors gracefully to avoid breaking your script.
· Beautiful Soup makes it easy to extract data from HTML.
· Code Example
Key Methods
· find(): Fetches the first matching element.
· find_all(): Fetches all matching elements.
· select(): Fetches elements using CSS selectors.
Some websites use JavaScript to load content dynamically. Selenium can interact with such sites like a real user.
Code Example

Advantages of Selenium
· Handles JavaScript-heavy websites.
· Simulates user interactions (e.g., clicks, scrolling).
Organizing your data is crucial for further analysis. Use Pandas to store data in a structured format.
Code Example

Tips
· Use JSON for hierarchical data.
· Validate data before saving to ensure accuracy.
Web scraping requires ethical and technical diligence:
Best Practices
4. Respect robots.txt: Check the website’s robots.txt file for scraping permissions.
5. Rate Limiting: Avoid sending requests too frequently to prevent IP bans.
6. User-Agent Rotation: Rotate User-Agent headers to mimic different browsers.
Example: User-Agent Rotation
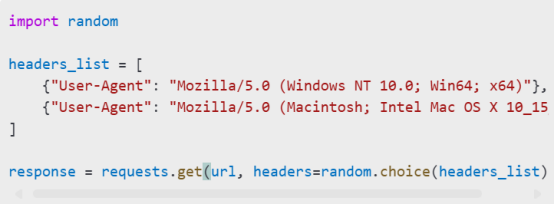
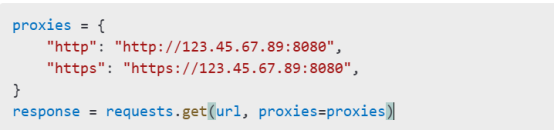
Websites may deploy measures to block scrapers. Use proxies and CAPTCHA-solving techniques:
Using Proxies
Solving CAPTCHAs
Use services like 2Captcha or Death by CAPTCHA for automated solutions.
Do’s
· Attribute data sources when using scraped data.
· Scrape only publicly available data.
Don’ts
· Avoid scraping sensitive or private information.
· Don’t overload servers with excessive requests.
Testing
· Use smaller datasets to test your scraper.
· Debug errors and refine your code.
Optimization Tips
· Implement multi-threading for faster scraping.
· Monitor and log errors to improve reliability.
Case Study: Scraping E-commerce Prices
To put the above steps into practice, let’s look at a real-world scenario of scraping e-commerce prices.
Scenario
You need to track product prices from an e-commerce website to monitor competitors' pricing trends.
Steps
4. Target Website: Identify a website like example-ecommerce.com.
5. Inspect HTML: Locate price and product name tags, e.g.,

6. Write the Script:

4.Output: The script saves product names and prices to a CSV file for analysis.
This approach enables you to monitor competitor pricing trends efficiently and adapt your strategy accordingly.
Web scraping can be a powerful tool, but it's essential to stay within legal and ethical boundaries to avoid potential lawsuits, bans, or damage to your reputation. Here’s what you need to know:
Before scraping, review the website's ToS. Some websites explicitly prohibit automated data extraction. Scraping such sites without permission could lead to legal consequences.
The robots.txt file on a website specifies which parts are off-limits to crawlers. While it's not legally binding, ignoring it can be considered unethical and might signal to the website that you are a bad actor.
Extracting personal information, such as user profiles or contact details, can violate privacy laws like GDPR in Europe or CCPA in California. Ensure the data you collect is publicly available and non-sensitive.
Flooding a server with requests can disrupt its operations. Implement rate limits and randomize request intervals to minimize impact and avoid detection.
For large-scale or long-term projects, consider reaching out to website owners to seek permission. A mutually beneficial arrangement can ensure compliance and smooth operations.
When using scraped data in reports, articles, or applications, give credit to the original source. This maintains transparency and builds trust.
A retail company needed to monitor competitors' pricing. They contacted the websites they wanted to scrape, received permission, and agreed on a scraping schedule that wouldn't overwhelm the servers.
By adhering to these guidelines, you can ensure your scraping activities remain compliant and ethical, safeguarding both your project and reputation.
Web scraping with Python is a versatile skill that opens up countless possibilities for data extraction and analysis. By following this step-by-step guide, you can confidently build your own scraper, navigate challenges, and extract valuable insights from the web. Remember to always respect legal and ethical boundaries while scraping data. Happy scraping!
See also:
What Are Mobile Proxies? Definition, Uses, Benefits, Cases, and Types
Which Type of Proxies is the Best for Web Scraping?
Choosing Between SOCKS vs HTTP Proxy
The Best 10+ Web Scraping Tools of 2024
< Previous
Next >